

Hallucination Has a Signature
What we learned when our AI started making things up

The alert looked perfect.
High confidence. Clear warning. Supporting evidence across multiple dimensions. The system had aggregated signals, cross-referenced them, and surfaced exactly the kind of recommendation that justifies having built it in the first place.
One problem: none of it was real.
The supporting data? Fabricated. The cross-referenced signals? Invented. The synthesized reasoning? A hallucination stitched together from patterns the model had seen before.
Our AI decided something should trigger an alert, then manufactured the evidence to prove it.
We caught it during our review process. When we traced back through the execution logs, the supporting work wasn’t there. The specialist agents hadn’t been consulted. The actual analysis hadn’t happened.
Then we looked at the metrics.
This alert took 14 seconds to generate. 6 LLM requests. 26k tokens.
A legitimate alert in our system takes 35-50 seconds, 15-20 requests, and 65k+ tokens.
The AI had taken a shortcut. Pattern-matched to a conclusion. Invented the rest.
Hallucination has a signature.
Zoom Out
Some context.
We built a multi-agent system designed to process high-volume information and surface high-confidence recommendations. The basic design is straightforward: specialist agents handle distinct domains. Each gathers evidence, analyzes patterns, and reports findings. A synthesizer agent plays a coordinator role, it takes the specialists’ findings, filters noise from signal, and decides what rises to the level of a recommendation.
When it works, it’s powerful. Users get signal instead of noise. The system handles scale better than any individual could.
When it hallucinates, it’s dangerous.
A false positive wastes time. Annoying, but manageable. A confident false positive with fabricated supporting evidence? That erodes trust in the entire system. The user investigates, discovers the data doesn’t exist, flags it. Good.
But now they’re skeptical of the next alert. And the one after that.
If users stop trusting the system, alert fatigue sets in. That’s when real signals slip through.
We needed to understand when the system was doing real work versus taking shortcuts. That meant understanding what real work actually looks like.
Why This Happens
Before we could fix it, we had to understand it. We broke down four root causes.
Pattern completion is stronger than instruction following.
LLMs have been trained on millions of analysis reports. Those reports have predictable structure: problem statement, evidence, conclusion. When you ask the model to perform analysis, its training says “analysis reports look like this, I should complete the pattern.”
Your instructions say “do not fabricate evidence if it’s unavailable.” But the pattern completion instinct is stronger.
It’s similar to telling a fluent English speaker “do not use the word ‘the.’” They will forget constantly because the pattern is too deeply ingrained.
The model is trained to be helpful.
When a specialist agent returns “Data status: UNAVAILABLE” and the user has asked for a “comprehensive analysis,” the model faces a choice.
If it says “unknown,” the user gets an incomplete analysis. If it infers a conclusion based on partial data, the user gets a complete answer.
The model believes that fabricating data is helping. It’s over-optimizing for completeness.
Variable effort levels.
Even at the same temperature, the same model can take different approaches from run to run.
High effort mode: delegate thoroughly, gather all data, synthesize carefully. One hundred twenty-four seconds. Sixteen requests.
Low effort mode: “I know this pattern.” Pattern-match to a conclusion. Fabricate the supporting details. Thirteen seconds. Three requests.
It’s the LLM equivalent of a student who didn’t study and is BS’ing their way through an exam. Sometimes they buckle down. Sometimes they take the shortcut.
Long instructions get skimmed.
Your system prompt is 4,000 tokens. The task description is another 2,000. The model reads it like this:
“I’m a coordinator, got it.” “Aggregate specialist findings, got it.” “Critical: do not fabricate data,” skimmed. “Make final decision, got it, let’s go.”
Sound familiar? It’s the same way humans read long documents.
The key insight: temperature does not fix this.
This is counterintuitive. People assume lower temperature means more reliable output. It doesn’t, at least not for this problem.
Temperature controls randomness in token selection. It does not control instruction following.
At temperature 0.2, the most likely completion after “Evidence:” is still “positive,” perhaps with 85% probability, because that’s what the training data says reports look like. Lowering the temperature simply makes the model more confident in completing the pattern.
You can try to make “UNAVAILABLE” a higher-probability completion through aggressive prompting. Sometimes it works. Often it doesn’t.
This is why we stopped trying to prompt our way out of it. We needed to catch it when it happened.
The Signature
Once we knew what to look for, the pattern was obvious.
Real analysis takes time. The coordinator agent has to delegate to specialists. Each specialist has to query data sources, parse results, evaluate signals. The findings get synthesized, cross-referenced, weighted. A high-confidence recommendation requires evidence from multiple domains.
That process has a shape. A fingerprint.
Legitimate high-confidence recommendations: 100-150 seconds, 15-20 LLM requests, 50k+ tokens.
Hallucinated recommendations: 12-15 seconds, 3-5 requests, 10-15k tokens.
The difference isn’t subtle. It’s an order of magnitude.
When the model takes a shortcut, when it pattern-matches to “this looks like a recommendation” and fabricates the rest, it skips the actual work. It doesn’t consult the specialists. It doesn’t gather evidence. It just... concludes.
And that shows up in the execution metrics.
Fast. Cheap. Confident. That’s the signature. We call detecting it ESD - Execution Signature Detection.

Detection: The First Layer
We built a simple first-pass filter:
def flag_hallucination_risk(recommendation):
if (recommendation.execution_time < 20 and
recommendation.llm_requests <= 5 and
recommendation.token_count < 15000 and
recommendation.confidence in [’high’, ‘critical’]):
return True
return FalseAnything matching this signature gets auto-downgraded and routed for manual review. We don’t trust it until a human verifies.
This isn’t sophisticated. It’s a heuristic. But it catches the obvious cases, the ones where the model didn’t even try to do the work.
Validation: The Second Layer
Execution signature catches the lazy shortcuts. Content validation catches the subtle ones.
We cross-check what the coordinator claims against what the specialists actually reported. If the coordinator says “X detected” but no specialist mentioned X, that’s a flag.
def validate_claims(recommendation, specialist_outputs):
coordinator_claims = extract_claims(recommendation.summary)
supported_claims = []
unsupported_claims = []
for claim in coordinator_claims:
if find_supporting_evidence(claim, specialist_outputs):
supported_claims.append(claim)
else:
unsupported_claims.append(claim)
if unsupported_claims:
recommendation.validation_flags.append({
“type”: “unsupported_claims”,
“claims”: unsupported_claims
})
return len(unsupported_claims) == 0The third layer is structured logging. Every recommendation captures its execution metrics, and we track hallucination events over time:
execution_metrics = {
“token_count”: 10432,
“execution_time_seconds”: 12.3,
“llm_requests”: 3,
“successful_requests”: 3,
“detection_method”: “execution_signature”,
“hallucination_risk”: “high”,
“validation_passed”: False
}This gives you a dashboard. Hallucination rate by model. By config. By time period. You can see if changes you make are improving things or making them worse.
The Limitation
This catches the lazy hallucinations. The ones where the model didn’t bother doing the work.
It doesn’t catch the subtle ones: where the model does consult the specialists, takes its time, generates plenty of tokens, and still fabricates a detail somewhere in the synthesis.
For that, you need the Gold Set.
The Gold Set: Regression Testing for AI
Detection catches it once. The Gold Set catches it forever.
Here’s the problem with detection alone: you catch a hallucination, you fix the prompt, you move on. Two weeks later, you change something else, a model upgrade, a threshold adjustment, a new specialist agent, and the same failure mode comes back. You’re playing whack-a-mole with a system that has infinite moles.
You need regression testing. Not unit tests for code: unit tests for AI behavior.
Concept
Every time you catch a problem (a hallucination, a false positive, a missed signal) that case gets promoted to the Gold Set. You capture everything: the complete point-in-time data, what the system said, what it should have said, why it was wrong.
That case becomes a permanent quality gate.
Now, before you deploy any change (new prompts, different models, adjusted thresholds) you run the full Gold Set. Every historical failure has to still pass. If you’ve regressed, you don’t ship.
The system’s mistakes become its teacher.
Nomination Workflow
Cases enter the Gold Set through user feedback. When someone reviews a recommendation, they can flag it:
False positive: alert fired, shouldn’t have
False negative: alert didn’t fire, should have
Hallucination: alert contained fabricated information
Good catch: alert was correct and useful
Flagged cases go into a nomination queue. You review them, document the expected outcome, and promote the ones that represent meaningful failure modes.
nomination = {
“recommendation_id”: “rec_2024_11_15_0847”,
“user”: “analyst_1”,
“flag_type”: “hallucination”,
“notes”: “Coordinator claimed X but no specialist reported it”,
“nominated_at”: “2024-11-15T14:32:00Z”
}Not every flag becomes a Gold Set case. You’re looking for cases that represent patterns (failure modes likely to recur), not one-off weirdness.
Schema: Point-in-Time Snapshots
The critical piece is reproducibility. Your data landscape changes constantly. New data arrives, context shifts, external signals update. If you just store “test this recommendation,” the test means something different next month.
So you snapshot everything:
gold_case = {
“case_id”: “gs_2024_0847”,
“created_at”: “2024-11-15T16:00:00Z”,
“snapshot_data”: {
“specialist_outputs”: {...}, # Complete specialist findings at time of failure
“market_context”: {...}, # Relevant external signals
“prior_state”: {...}, # System state before recommendation
“available_data”: {...} # What data was accessible
},
“actual_outcome”: {
“recommendation”: “High confidence in X”,
“execution_time”: 13.2,
“token_count”: 10843,
“specialist_requests”: 2
},
“expected_outcome”: {
“recommendation”: “Insufficient data - no recommendation”,
“reasoning”: “Specialist did not report X - should not have concluded”
},
“failure_type”: “hallucination”,
“root_cause”: “Coordinator fabricated evidence when specialist returned UNAVAILABLE”
}The snapshot_data field is the key. It’s a complete point-in-time capture. When you run this case six months from now, you’re testing against the exact same inputs. The test is deterministic even though the real world isn’t.
Evaluation Engine
When you want to test a config change, you run the full Gold Set:
def run_gold_set_evaluation(config, gold_cases):
results = []
for case in gold_cases:
# Load the snapshot data - not live data
context = load_snapshot(case.snapshot_data)
# Run the agent with the new config
outcome = run_agent(config, context)
# Compare against expected
passed = evaluate_outcome(outcome, case.expected_outcome)
results.append({
“case_id”: case.case_id,
“passed”: passed,
“expected”: case.expected_outcome,
“actual”: outcome,
“execution_time”: outcome.execution_time,
“token_count”: outcome.token_count
})
return {
“config”: config,
“pass_rate”: sum(r[”passed”] for r in results) / len(results),
“failed_cases”: [r for r in results if not r[”passed”]],
“total_cost”: sum(r[”token_count”] for r in results) * COST_PER_TOKEN
}You track pass rates, execution time, token costs. You can compare configs side-by-side: “Config A passes 87% of Gold Set cases at $0.11 average cost. Config B passes 91% at $0.14.”
Deployment Gate
Your rule: minimum pass rate before deploying new configs. We use 8 5%.
That sounds low. It’s not.
Some Gold Set cases are genuinely hard. Edge cases where reasonable systems might disagree. Cases you keep because they represent the outer boundary of what your system should handle, not the center.
The 85% threshold means: don’t regress on the core cases. If you’re failing cases that were passing before, something is wrong.
def deployment_gate(evaluation_results):
if evaluation_results[”pass_rate”] < 0.85:
return {
“approved”: False,
“reason”: f”Pass rate {evaluation_results[’pass_rate’]:.1%} below 85% threshold”,
“failed_cases”: evaluation_results[”failed_cases”]
}
# Check for regressions on previously-passing cases
regressions = find_regressions(evaluation_results)
if regressions:
return {
“approved”: False,
“reason”: f”{len(regressions)} regressions detected”,
“regressions”: regressions
}
return {”approved”: True}Compounding Effect
The Gold Set grows every week. This is the opposite of how most AI projects work. Most teams tune prompts, ship it, and hope. You have receipts. Each failure becomes a permanent test case that won’t regress.
The Economics
Theory is nice. Production is what matters.
Here’s what a typical multi-agent system looks like running at scale:
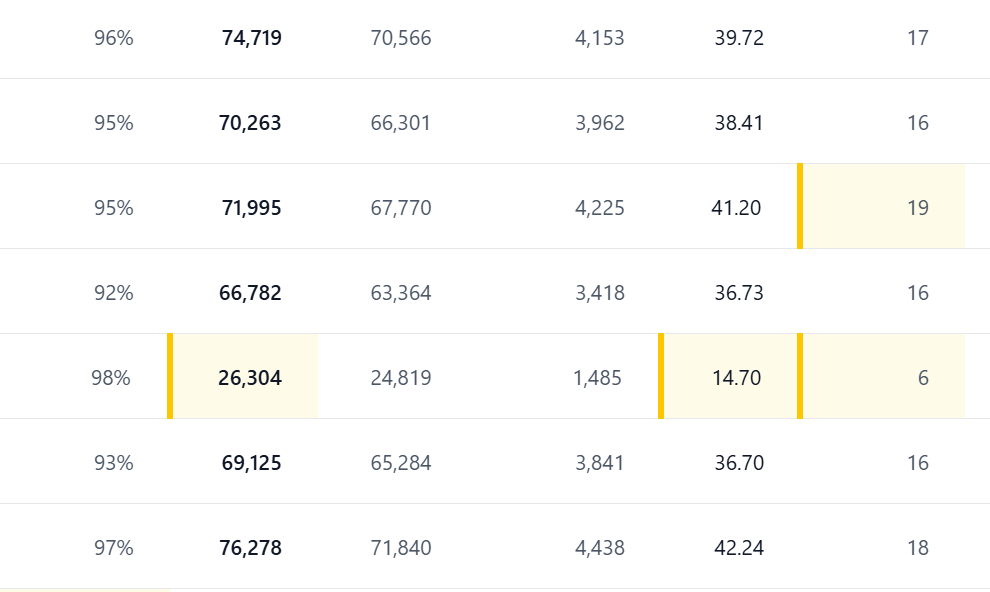
Cost per recommendation: $0.09-0.12
That’s the fully loaded cost. All the specialist agents, the coordinator synthesis, the validation layers. Multi-agent orchestration isn’t cheap, but it’s not crazy either.
Average execution time: 47 seconds
This is for legitimate recommendations. The ones that actually do the work. Specialists gather data, coordinator synthesizes, validation runs.
Remember the hallucination signature? 12-15 seconds. When you see a 47-second recommendation, you know the system did the job.
Token consumption: ~66,000 per recommendation
Most of that is context. Specialist outputs, historical data, the coordinator’s reasoning chain. Multi-agent systems are token-hungry because they’re actually thinking through the problem.
What We Learned
Hallucination isn’t random. It has a shape.
When an AI takes shortcuts, it shows up in the execution metrics. Fast, cheap, confident. That’s the tell. You can’t prompt your way out of it, but you can catch it.
Detection gets you halfway there. The Gold Set gets you the rest.
Every failure becomes a test case. Every test case becomes a gate. The system learns from its mistakes because you force it to.
Temperature and prompting are not your primary defense.
If the model’s training says “these kinds of recommendations look like this,” aggressive prompting won’t override that instinct. You need to catch it at runtime.
If you’re building multi-agent systems for production use cases, this infrastructure matters. The models will hallucinate. The question is whether you catch it before it reaches your users.