

Uncovering Commercial Real Estate Insights with ChatGPT and Streamlit
Analyzing Edgar data and building interactive charts to make informed investment decisions - 2020-BNK25

In the ever-evolving world of commercial real estate, the ability to analyze vast amounts of data efficiently and accurately has become increasingly crucial for analysts and investors alike. Traditional methods of data analysis can be time-consuming and labor-intensive, often leaving professionals searching for more efficient solutions. Enter ChatGPT, an advanced AI language model designed to provide valuable insights and expert knowledge across various industries, including commercial real estate. By leveraging ChatGPT's capabilities, commercial real estate analysts can quickly and effectively gather insights from large datasets, allowing them to make informed decisions and stay ahead of the competition.

This article aims to demonstrate the potential of ChatGPT in the realm of commercial real estate analytics, showcasing how it can be utilized to extract valuable insights from Edgar data, a rich source of financial information for investors. By giving ChatGPT the context of a commercial real estate analyst and investor, you can harness its power to identify trends, risks, and opportunities that may impact your investment decisions. Furthermore, this article will also explore the integration of Streamlit, a powerful data visualization tool, to transform ChatGPT-generated insights into interactive charts, enabling you to visualize data in a more engaging and insightful manner. So, let's dive in and uncover the potential of ChatGPT and Streamlit in revolutionizing commercial real estate analytics.
Setting the Stage for ChatGPT
Before diving into the analysis, it's essential to provide ChatGPT with the appropriate context as a commercial real estate analyst and investor. This ensures that the AI model understands the domain-specific information and can generate meaningful insights from the Edgar data. So in this case, we will do two distinct things: pre-train and inform about the data. If you haven’t read our post on pre-training, check it out here, it’s a good primer!
Respond as though you are a portfolio manager at an alternative asset management firm who specializes in investing in CMBS deals.Now, on to the data. In this article, we are going to look into the CMBS Conduit Transaction 2020-BNK25 - Bank of America Merrill Lynch Commercial Mortgage Trust. We are going to use data from Edgar, which DealCharts does a great job of ripping and putting into Snowflake. I have a count.co dashboard with the data we will use here: 2020-BNK25.
The Edgar data, provided in CSV format, contains a wealth of financial information about commercial real estate investments. It may include variables such as property types, locations, occupancy rates, rental income, property values, and financial ratios. By presenting this data to ChatGPT, you enable the AI model to analyze the information and provide relevant insights based on the variables at hand.
So let’s do it!
Analyzing the data with ChatGPT
The following is an example of a CSV of Edgar data we have access to:
CIK,COMPANY_NAME,FILING_ID,FILING_DATE,CREATED_AT,FORM_SUBMISSION_ID,ASSETTYPENUMBER,ASSETNUMBER,REPORTINGPERIODBEGINNINGDATE,REPORTINGPERIODENDDATE,ORIGINATORNAME,ORIGINATIONDATE,ORIGINALLOANAMOUNT,ORIGINALTERMLOANNUMBER,MATURITYDATE … [the rest of the data from the count.co dashboard]And here is the first response…this still just blows me away
Thank you for providing the sample CSV data. Based on the available columns in the dataset, we can propose the following prompts to extract insights from the Edgar data:
"Analyze the trends in original loan amounts across different originator names and identify any patterns or correlations."
"Calculate the average original interest rate percentage for each originator and discuss any potential reasons for variations in interest rates."
"Determine the relationship between original loan amount and maturity date, and identify any potential risks or opportunities for investors."
"Examine the distribution of lien position securitization codes and loan structure codes across different originators and identify any patterns."
"Investigate the relationship between payment status loan codes and other financial variables such as original interest rate percentage, original loan amount, and scheduled principal balance securitization amount."
"Calculate the average servicer trustee fee rate percentage for each primary servicer and discuss the implications for investors."
These prompts will help you gain insights into the Edgar data related to the commercial real estate market. Remember to adjust the prompts according to the specific information available in the dataset, ensuring that ChatGPT has the necessary context to provide relevant and accurate insights.
Okay cool, why don’t we focus on #5. This prompt focuses on the payment status of the loans, which is a critical aspect for investors to assess the performance and risk of their investments. By examining the relationship between payment status and other financial variables, investors can gain insights into potential risk factors, identify trends, and make more informed decisions regarding their commercial real estate investments. This analysis can help investors better understand the underlying risks and opportunities in the market, contributing to more robust investment strategies.
Assuming I have a CSV file in the format above, named loans.csv. Can you write the code for a streamlit dashboard that would present a series of charts that would help explain: "Investigate the relationship between payment status loan codes and other financial variables such as original interest rate percentage, original loan amount, and scheduled principal balance securitization amount."To create a Streamlit dashboard that investigates the relationship between payment status loan codes and other financial variables, follow the instructions below. Make sure you have installed Streamlit and Pandas using pip before proceeding:
pip install streamlit pandasCreate a Python script called dashboard.py and include the following code:
import pandas as pd
import streamlit as st
import seaborn as sns
import matplotlib.pyplot as plt
# Read the CSV data
data = pd.read_csv("loans.csv")
# Set the title of the dashboard
st.title("Payment Status Loan Code Analysis")
# Display a description of the dataset
st.write("This dashboard investigates the relationship between payment status loan codes and other financial variables such as original interest rate percentage, original loan amount, and scheduled principal balance securitization amount.")
# Display the dataset
st.write(data)
# Group the dataset by payment status loan codes
grouped_data = data.groupby("PAYMENTSTATUSLOANCODE")
# Display summary statistics for each group
st.subheader("Summary Statistics by Payment Status Loan Code")
st.write(grouped_data[["ORIGINALINTERESTRATEPERCENTAGE", "ORIGINALLOANAMOUNT", "SCHEDULEDPRINCIPALBALANCESECURITIZATIONAMOUNT"]].describe())
# Create a scatter plot matrix to visualize relationships between the variables
st.subheader("Scatter Plot Matrix")
fig, ax = plt.subplots(figsize=(12, 8))
sns.pairplot(data, vars=["ORIGINALINTERESTRATEPERCENTAGE", "ORIGINALLOANAMOUNT", "SCHEDULEDPRINCIPALBALANCESECURITIZATIONAMOUNT"], hue="PAYMENTSTATUSLOANCODE", diag_kind='hist', corner=True)
st.pyplot(fig)
# Create a correlation heatmap
st.subheader("Correlation Heatmap")
fig, ax = plt.subplots(figsize=(8, 6))
sns.heatmap(grouped_data[["ORIGINALINTERESTRATEPERCENTAGE", "ORIGINALLOANAMOUNT", "SCHEDULEDPRINCIPALBALANCESECURITIZATIONAMOUNT"]].corr(), annot=True, cmap="coolwarm", cbar_kws={"label": "Correlation"})
st.pyplot(fig)Great start, I went on to ask it to add a couple other things, like filters by Servicer and lay out the charts in multiple columns, and first thing that jumped out at me was a typical problem with data in this space - similar names. In this case, we had two versions of Wells Fargo Bank in the Servicer column - NA and N.A.

Easy enough to fix, but, let’s see if ChatGPT can.
I seem to have a couple similar, but ultimately same named companies in the PRIMARYSERVICERNAME, can you combine them into one?
Wells Fargo Bank, NA
Wells Fargo Bank, N.A.and it cleaned that up for us quickly! I’ll have it clean up KeyBank at some point too😄
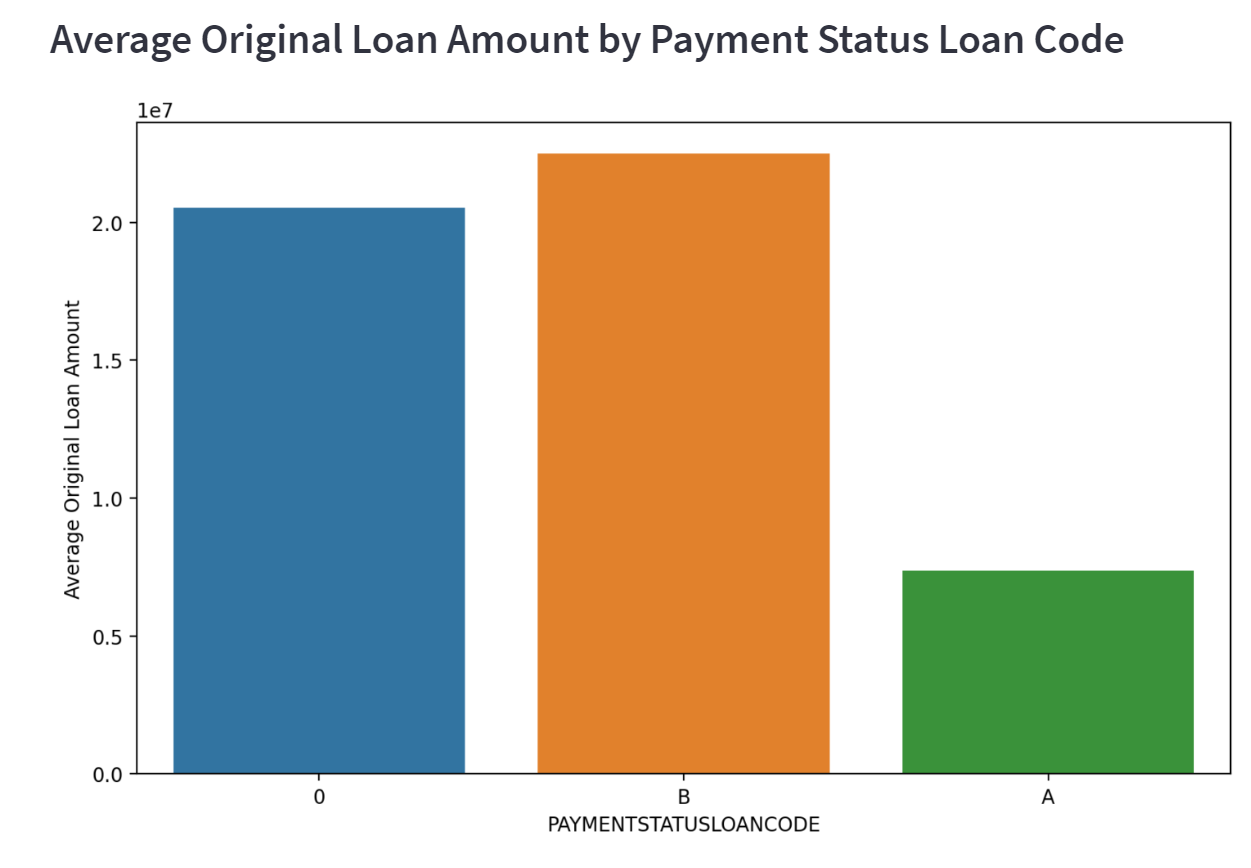
Now, what about the charts? Some were maybe a little messy, could use some better formatting, but, interesting nonetheless:

Building upon the Streamlit Dashboard
Okay, super cool - seemed to generate some charts related to the original question. How valuable these are, is a different question…but, it feels like a good start at least. I also only provided Loan information at this point, we also have access to performance data related to the properties held by this loan. Let’s see what it does with that. Given we have had a pretty lengthy conversation with our ChatGPT agent at this point, I do not believe I need to add additional context. Let’s ask it something broad, and let it be creative:

Here’s how it responded:
We can create a dashboard that displays key insights and metrics from these two files. Here's a suggestion of what we can include in the dashboard:
Total number of properties and loans.
Aggregate metrics:
Total original loan amount.
Average original interest rate.
Total net rentable square feet.
Total valuation amount.
Breakdowns by property and loan attributes:
Number of properties by property type.
Number of properties by state.
Number of loans by originator name.
Distribution of loan maturity dates.
Performance metrics:
Average debt service coverage ratio (DSCR).
Average occupancy percentage.
Average net operating income (NOI).
Top properties/loans based on different criteria:
Top 5 properties by valuation amount.
Top 5 loans by original loan amount.
To create this dashboard, you'll need to preprocess the data, join the datasets on relevant columns, and calculate the necessary metrics. Then, you can use a data visualization tool like Tableau, Power BI, or even Excel to create the visualizations and organize them into a dashboard.
So, clearly it has already forgotten that we have already built some dashboards with Streamlit - but I will give it a pass. (Side note, I’m waiting to get a key for Pinecone.ai - which apparently can give ChatGPT some better long and short term memory through tools like AutoGPT. Soon as I have had a chance to explore that I will share the details with you, stay tuned! 🚀)
Seems like pretty basic info that should in fact be available in those two files. Build it for me Albert! (Yes…I named our ChatGPT CMBS Expert Albert! 😄 )
Let's create a dashboard in streamlit with that informationAlbert came back with code for a pretty detailed dashboard covering off just about all of the metrics it described - a couple charts below:
Much like last time, I asked it to add some filtering capability, and much to my surprise, it did remember to leave in the code about filtering out the NA/N.A. issue with Wells Fargo. Of course, I am just giving it a portion of the actual file, so it cannot go in and do a quality check on all of the fields, but, I am fine with that.
Albert also included the list of top 5 properties, which quickly pointed me to another data error - seemingly some duplicates:

Doing a little more digging though, there are multiple rows for individual notes for a given loan, which makes sense. Let’s see what Albert can do with that:
In the Loan file, there are sometimes two loans that refer to individual notes on the same ultimate loan. Can we roll these up to one? They look like this, where we have ASSETNUMBER = 1 and 1A, there would be other cases like 2 and 2A or 6 and 6A, etc.It recommended I roll these up with a cleanup script. I may have chosen to do it in the Streamlit dashboard itself, manipulating the dataframes, but, in ChatGPT we trust. Let’s try it:
To roll up the loans with the same ASSETNUMBER (e.g., 1 and 1A, 2 and 2A), you can use the following approach:
Extract the base ASSETNUMBER (e.g., remove the trailing 'A') and create a new column.
Group the data by the base ASSETNUMBER and sum the numerical columns like
ORIGINALLOANAMOUNTand other relevant columns.Replace the existing data with the rolled-up data.
It then detailed out some code:
import pandas as pd
# Load the loan data into a Pandas DataFrame (assuming it's in a CSV format)
data = pd.read_csv("loan_data.csv")
# Step 1: Extract the base ASSETNUMBER
data['BASE_ASSETNUMBER'] = data['ASSETNUMBER'].str.extract(r'(\d+)')
# Step 2: Group the data by the base ASSETNUMBER and sum the numerical columns
grouped_data = data.groupby('BASE_ASSETNUMBER').agg({
'ORIGINALLOANAMOUNT': 'sum',
# Add other numerical columns to be summed
})
# Step 3: Replace the existing data with the rolled-up data
data = data.drop(columns=['ORIGINALLOANAMOUNT']).merge(grouped_data, on='BASE_ASSETNUMBER', how='left')
# Save the rolled-up data to a new CSV file
data.to_csv("rolled_up_loan_data.csv", index=False)Again, not really perfect, I do not care about just ORIGINALLOANAMOUNT being merged, there are a number of fields we are potentially using here. So I asked it to look for other columns we could aggregate:
In the example CSV I had provided, can you see any other columns besides ORIGINALLOANAMOUNT that differ and should be aggregated?Albert said:
Here's a list of columns that differ between the two rows and should be aggregated:
ORIGINALLOANAMOUNT
PERIODICPRINCIPALANDINTERESTPAYMENTSECURITIZATIONAMOUNT
REPORTPERIODBEGINNINGSCHEDULELOANBALANCEAMOUNT
TOTALSCHEDULEDPRINCIPALINTERESTDUEAMOUNT
SCHEDULEDINTERESTAMOUNT
REPORTPERIODENDACTUALBALANCEAMOUNT
REPORTPERIODENDSCHEDULEDLOANBALANCEAMOUNT
Alright, with the help of ChatGPT, we've successfully built a foundation for our commercial real estate data dashboard. We've set up the necessary data roll-ups, and it's now up to you to create the charts you'd like to see, such as DSCR, NOI, and more. Remember, you can always consult ChatGPT for assistance with your chart creation process!
As a teaser for our next blog post, we're going to dive into something even more exciting – plotting the 2020-BNK25 property locations on a map! We’ll have Albert show us how we can do that. Prepare to unlock the potential of geospatial analysis in commercial real estate analytics. Be sure to click below to make sure you are notified when that post comes out!
Stay tuned for this fascinating exploration and Happy Prompting!